ごきげんよう。
今回はPostgreSQLのB-Treeインデックスについて検証してみました。
データベースについて勉強した方は
以下の本を読んだことがあるかもしれません。
達人に学ぶDB設計徹底指南書 初心者で終わりたくないあなたへ
著者:ミック
2012年初版発行
この本によると
以下の場合はインデックスが利用できないと記載されています。
- インデックス列に演算を行っている
- ORを用いている
- 後方一致、または中間一致のLIKE述語を用いている
# 他にもあるんですが、とりあえずこの3つをピックアップしました
LIKE述語の件は知ってたんですが、
演算とORについて知らなかったので合わせて検証してみました。
【環境】
OS:windows8.1
DB:PostgreSQL9.4.2
PostgreSQLのチューニング一切なし(デフォルトのまま)
【事前準備】
テーブル環境
CREATE TABLE index_test
(
id integer PRIMARY KEY,
num integer NOT NULL,
moji text NOT NULL
)
CREATE INDEX index_num ON index_test(num);
CREATE INDEX index_moji ON index_test(moji);
データは前回記事
Javaで重複なしのランダムな値をファイル出力する
http://show-surumegohan.blogspot.jp/2015/06/java.html
で作成した
100万件のCSVファイルです。
中身は以下のような感じです。
1,742983,hoge742983
2,903173,hoge903173
3,738660,hoge738660
:
:
999998,761436,hoge761436
999999,927983,hoge927983
1000000,128247,hoge128247

【検証1:インデックス列に演算を行っている】
num列の値を演算して検索してみます。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE num * 2 > 8000000;
"Seq Scan on index_test (cost=0.00..21370.00 rows=333333 width=18) (actual time=110.917..110.917 rows=0 loops=1)"
" Filter: ((num * 2) > 8000000)"
" Rows Removed by Filter: 1000000"
"Planning time: 0.081 ms"
"Execution time: 110.938 ms"

Seq Scan(シーケンススキャン)が走ってしまっています。
# Seq Scanはテーブル内のデータをすべて参照する
で、この場合の対応策としては
WHERE句はあくまでnum列をそのまま呼び出して
同値の式変形をします。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE num > 8000000 / 2;
"Index Scan using index_num on index_test (cost=0.42..8.44 rows=1 width=18) (actual time=0.004..0.004 rows=0 loops=1)"
" Index Cond: (num > 4000000)"
"Planning time: 0.120 ms"
"Execution time: 0.019 ms"

無事にindex_numインデックスが使用されました。
演算が必要な場合は列を呼び出すときはそのままの状態で呼び出してあげましょう。
【検証2:ORを用いている】
本によると
ORを用いた場合はインデックスが利用できません。と明記してあります。
ということでやってみます。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE num = 12345 OR num = 67890 OR num = 987654;
"Bitmap Heap Scan on index_test (cost=13.30..25.16 rows=3 width=18) (actual time=0.030..0.032 rows=3 loops=1)"
" Recheck Cond: ((num = 12345) OR (num = 67890) OR (num = 987654))"
" Heap Blocks: exact=3"
" -> BitmapOr (cost=13.30..13.30 rows=3 width=0) (actual time=0.024..0.024 rows=0 loops=1)"
" -> Bitmap Index Scan on index_num (cost=0.00..4.43 rows=1 width=0) (actual time=0.012..0.012 rows=1 loops=1)"
" Index Cond: (num = 12345)"
" -> Bitmap Index Scan on index_num (cost=0.00..4.43 rows=1 width=0) (actual time=0.007..0.007 rows=1 loops=1)"
" Index Cond: (num = 67890)"
" -> Bitmap Index Scan on index_num (cost=0.00..4.43 rows=1 width=0) (actual time=0.004..0.004 rows=1 loops=1)"
" Index Cond: (num = 987654)"
"Planning time: 0.105 ms"
"Execution time: 0.064 ms"

PostgreSQL9.4.2だと、
Bitmap Heap Scan
が動きました。
で、OR句はBitmapOr が走ってるようで
さらにその中で
Bitmap Index Scan
がORの回数だけ走っているようです。
つまり
ORでもインデックスは作用する
ようです。
# 本が発行された2012年の段階だとダメだった?
ちなみにミックさんは
こういうときはINにすればよいと記載しています。
なのでやってみました。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE num IN (12345,67890,987654);
"Index Scan using index_num on index_test (cost=0.43..25.33 rows=3 width=18) (actual time=0.008..0.018 rows=3 loops=1)"
" Index Cond: (num = ANY ('{12345,67890,987654}'::integer[]))"
"Planning time: 0.173 ms"
"Execution time: 0.052 ms"

ORに比べてINだとシンプルに
Index Scan
が走ってますね。
中をよく見てみると
Index Cond: (num = ANY ('{12345,67890,987654}'::integer[]))
となっていてANYでまとめられてるようです。
ただ、今回のケースだと実行速度はそんなに変わらないみたいです。
もっと複雑な条件が重なるとINの方がはやいんでしょうかね?
【検証3:後方一致、または中間一致のLIKE述語を用いている】
これは私も知ってたんですが
やってみたら意外な結果がでました。
まずは後方一致から。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE moji LIKE '%ge12345';
"Seq Scan on index_test (cost=0.00..18870.00 rows=100 width=18) (actual time=7.713..135.400 rows=1 loops=1)"
" Filter: (moji ~~ '%ge12345'::text)"
" Rows Removed by Filter: 999999"
"Planning time: 0.079 ms"
"Execution time: 135.419 ms"

Seq Scanが選ばれてしまっています。
インデックスが作用してませんね。
次に中間一致をやってみます。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE moji LIKE '%ge12345%';
"Seq Scan on index_test (cost=0.00..18870.00 rows=100 width=18) (actual time=1.423..134.443 rows=11 loops=1)"
" Filter: (moji ~~ '%ge12345%'::text)"
" Rows Removed by Filter: 999989"
"Planning time: 0.101 ms"
"Execution time: 134.470 ms"
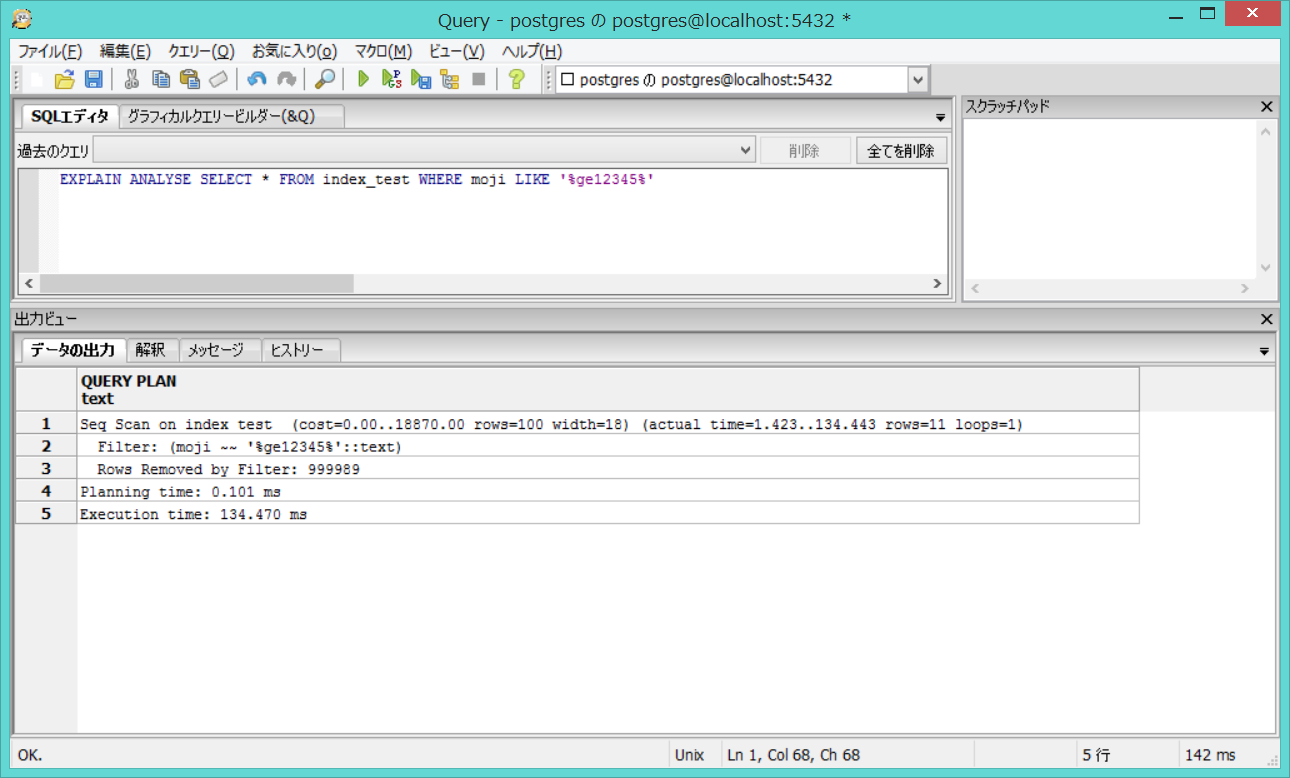
この場合もSeq Scanが選ばれてしまっています。
さて、本にはこんなことが書いてあります。
LIKE述語を使うときは前方一致検索の場合のみ索引が使用されます。
私もその知識だったのですがひとまずやってみました。
前方一致をやってみます。
EXPLAIN ANALYSE SELECT * FROM index_test WHERE moji LIKE 'hoge12345%';
"Seq Scan on index_test (cost=0.00..18870.00 rows=100 width=18) (actual time=1.395..119.152 rows=11 loops=1)"
" Filter: (moji ~~ 'hoge12345%'::text)"
" Rows Removed by Filter: 999989"
"Planning time: 0.104 ms"
"Execution time: 119.177 ms"

前方一致のクエリを投げたつもりなのですが
結果はSeq Scanが走っています。
なんでなんだぜ??
前方一致で似たようなクエリを何パターンかやってみたんですが
Seq Scanが走りました。
これはなんでなんでしょう??
誰か教えてください。。。
というわけで
検証の結果、本の内容と若干異なる結果がでちゃいました。
2012年の本なので、2015年現在ではRDBも進化してるということでしょうか?
LIKE述語の前方一致の件、、誰か教えてください・・・
=================
追記:
ありがたいことにコメントをいただけました。
次の記事でいただいたコメントをもとに再検証しました。
PostgreSQL ロケールとLIKE述語そしてpgAdminでの注意
ごきげんよう。LIKEの前方一致ですが、
返信削除CREATE INDEX index_moji ON index_test(moji text_pattern_ops);
と、列名の後に text_pattern_ops を付けてインデックスを作り直してみて下さい。
こちらでやったら、ロケールが「C」のDBなら初めからIndex Scanで、
ロケールがJapanese_Japan.932のDBでは記事と同様で、…ops付けたらインデックスが使われました。
先日のアンカンファレンスまとめ記事、ありがとうございました。
私は夏目が好きですww
Koda
ごきげんよう。
返信削除コメントありがとうございます!
ご指摘の通り
ロケールを調べてみたら
Japanese_Japan.932
になってました・・・
次回記事で検証させていただきますね!
アンカンファレンスの記事も読んでいただいたようでありがとうございます。
夏目・・・とは?
ひだまりスケッチの…です
返信削除@tsuyu1222さんのアイコンだったので、知ってるかと…スミマセン
あ、あー!
返信削除はい。
ひだまりの夏目さんですねw
ひだまりはハニカムしか見てないのですが、夏目さんは存じております。
かわいいですよね。
ちなみに私は宮子さんと乃莉さんが好きですw